I’ve heard a lot of talk about “can you run Cyphal over X?” where x has been things like serial (UART), ARINC-825, DDS, MQTT, even PCI. I’m wondering if, instead of a tackling each query individually, we shouldn’t develop a generalized concept mapping guide for Cyphal? This guide would answer questions like how to adapt RPC-style calls, how to adapt pub-sub semantics, when to develop a transport layer and when/how to reuse a given transport layer, etc. It would also address the “why?” question where sometimes people are chasing a foolish consistency and other times there are real benefits not being considered.

Such a guide could be added either as a non-normative section of the Transport chapter of the Specification (a large blue box), or as a new chapter in the Cyphal Guide.
The underlying transport should ideally have some built-in means of segregation of distinct data flows, such that agents communicating over flow X would be unaffected by other agents communicating over flow Y unless X is Y. In the existing transport implementations, the flows are identified as follows:
- Cyphal/UDP: the flow is identified by its IP multicast group address.
- Cyphal/CAN: the flow is identified by its CAN ID.
- Cyphal/serial: there is no built-in flow segregation capability in this transport layer, so this logic is entirely implemented by the protocol stack itself.
In a well-designed Cyphal transport, the flow identifier would be constructed differently for subject transfers and service transfers. This already implies that the flow identifier is a function of which kind of transfer it represents; in the case of Cyphal/CAN and Cyphal/UDP, for example, this is done via a separate selector bit that is set for services but not for messages, or vice versa. For subject transfers specifically, it is paramount that the flow identifier is a function of the subject-ID; at the same time, it should be invariant to the identity of the publishing node to uphold the principles of DCPS.
A diligent reader would point out that the latter clause is not upheld in Cyphal/CAN, as the CAN ID depends on the identity of the publishing node (its node-ID is included in the CAN ID). For CAN specifically, this is not a problem because all commercially available implementations of CAN allow masking away irrelevant segments of CAN ID, thereby removing the dependency of the flow identifier on the identity of the publishing node.
For service transfers, the flow identifier has to be dependent on the identity of the node that is the recipient of the transfers (as service transfers are exclusively point-to-point). The presence of the service-ID in the flow identifier is entirely optional, as the receiving node can cheaply filter out irrelevant service transfers that appear in the selected flow. This works for service transfers but not for message transfers because the former are inherently point-to-point, and therefore a node will only have to filter through service transfers that are already addressed to it, excluding broadcast traffic that appears in the case of message transfers.
One example of the above principles is the definition of the Cyphal/UDP transport, where the multicast group address contains the service/message selector bit plus the subject-ID for messages and the destination node-ID for services; see this discussion: [Cyphal/UDP] Architectural issues caused by the dependency between the node's IP address and its identity - #60 by scottdixon
For example, if one were to construct a Cyphal/MQTT transport, then the MQTT topic names could conceivably be defined as follows:
- For message transfers (i.e., subjects):
m0000, where 0000 stands for the subject-ID value. - For service transfers, either:
-
s0000, where 0000 stands for the destination node-ID value. -
s0000:0000, where the first 0000 stands for the service-ID and the second stands for the destination node-ID.
-
The above principles allow one to reify the route specifier. To refresh the memory of the transport model, here is a relevant diagram from the Specification:
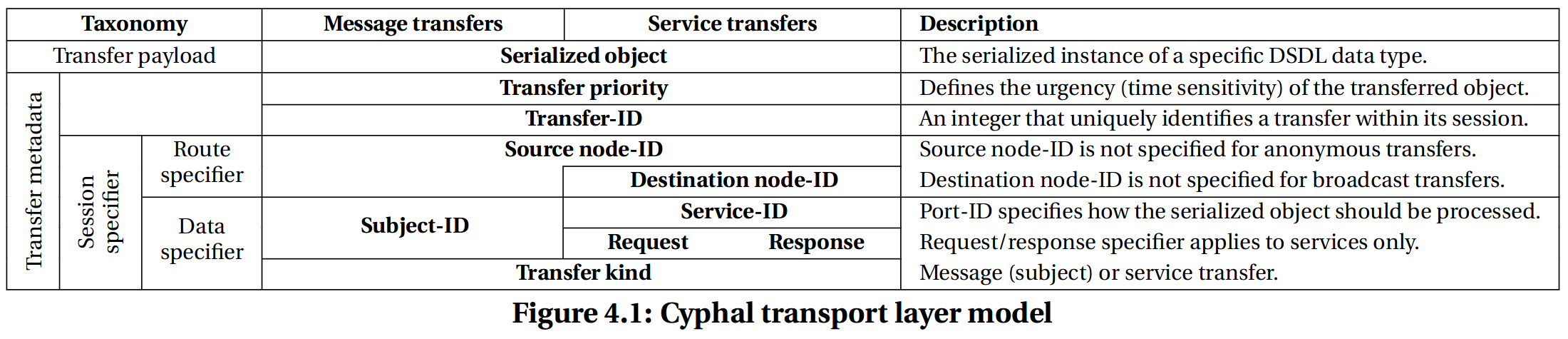
There are other members of the transport layer model that require representation. As they do not affect the routing of the data in the network, they are, to an extent, representable in a unified manner that is independent of the underlying transport implementation. One way to approach this is to use the existing transport frame header format that is already leveraged by Cyphal/UDP and Cyphal/serial; one thing to notice here is that these two transports are very different in their construction and yet they are able to leverage the identical frame header format. Said frame header format is defined as follows (DSDL notation):
uint4 version # <- 1
void4
@assert _offset_ == {8}
uint3 priority
void5
@assert _offset_ == {16}
uint16 source_node_id
uint16 destination_node_id
uint16 data_specifier # subject-ID | (service-ID + request/response discriminator).
@assert _offset_ == {64}
uint64 transfer_id
@assert _offset_ == {128}
uint31 frame_index
bool end_of_transfer
uint16 user_data
# Opaque application-specific data with user-defined semantics. Generic implementations should ignore
@assert _offset_ % 16 == {0}
uint8[2] header_crc16_big_endian
@assert _offset_ / 8 == {24} # Fixed-size 24-byte header with natural alignment for each field ensured.
@sealed
Certain transports already represent some of the above fields as transport-specific data items, which creates redundancy. Said redundancy is not considered to be a significant shortcoming. For instance, the destination node-ID would be redundant to represent in the header for most transports, but we overlook it on purpose. The priority field is likewise already represented in the QoS field in Cyphal/UDP.
Some transports may have hard limits on the maximum transmission unit per frame, while others have no such restrictions. For instance, the MTU limit affecting CAN and UDP transports requires the corresponding Cyphal transport implementations to provide built-in means of decomposing long transfers into several frames with the subsequent process of their reassembly. The multi-frame transfer reassembly state machines can get very complex in comparison to the rest of the stack; therefore, if the transport provides built-in means of exchanging arbitrarily long batches of data, it is desirable to make use of them as it may enable significant simplification of the transport specification. This is why Cyphal/serial does not support multi-frame transfers, allowing arbitrarily-long transport frames instead. In line with the earlier considerations of acceptable header redundancy, the Cyphal/serial frame header still contains the fields pertaining to multi-frame transfer reassembly, which are simply unused. A hypothetical Cyphal/MQTT implementation would likely be similar to Cyphal/serial in this respect.
As Cyphal is designed for use in high-integrity systems, its transport implementations are likely to require end-to-end data integrity enforcement. To this end, existing Cyphal/UDP and Cyphal/serial implementations add a mandatory 32-bit CRC-32C Transfer-CRC field at the end of the serialized transfer payload. This measure enables protection against data corruption in the protocol stack buffers as well as against incorrect reassembly of multi-frame transfers. Implementations of new transport layers would likely benefit from a certain degree of consistency in this sense as well.