Whoops! I see that Scott replied ahead of me, and he doesn’t appear to like this proposal. However:
While I don’t know what @pavel.kirienko will think about modifying the standard like this, I do have to say that this is the best solution I’ve seen so far. It is the only one I’ve read that tries to approach some sort of compromise, and at a superficial level it seems quite reasonable to me.
My only question is: @tridge if this actually is implemented, I would want vendors/firmware to support both at configuration time - otherwise the fragmentation would becoming annoying. Would you be okay with that? Whether or not ardupilot would implement support for consuming the non-fixed counterparts is, I think, up to you.
Either way: I’d like to thank you for coming up with a solution that doesn’t involve restating our own existing ideas again and again. It really helps to add novel ideas to the discussion.
and I thank you for doing so! now I’ll steal it
note that there are several reserved bits. Which particular one did you have your eyes on? I picked bit 23 for this proposal, but it could just as easily be one of the other ones.
I’d be perfectly happy to reserve a range of values for the 13 bit subject-ID field for use by the sensor messages instead of grabbing one of the reserved bits. We don’t need 8192 IDs, so the reserved bit is grabbing a lot more space than it needs, but @pavel.kirienko did not seem keen on taking a chunk of that 13 bit space, so this was an alternative.
I2C is really quite different. I2C is a master/slave setup, where devices only answer when they are asked to do something (at least in normal i2c usage, there are other ways to use i2c).
In UAVCAN we really want a sensor to be able to immediately start sending as soon as it is powered up. We have seen cases of sensors browning out in flight and resetting, and we don’t want to wait around for a “we haven’t heard from that sensor in a while, maybe we should probe it and see if it needs reconfiguring” cycle.
one of the things that is really missing in v1 is the semantic CRC we have in mavlink 1.0 and 2.0. For those who don’t know about that, the way it works is this:
the 16 bit mavlink CRC is seeded with the structural CRC
this means that if someone is using a different message (different xml) for the same ID then it will almost certainly give a crc failure and the message is discarded by the recipient.
One thing that I regret is seeding the whole of the CRC with the structural CRC. I should have seeded only 8 bits of it, and left 8 bits as a “just the data” CRC. That would mean mavlink routers could get a checksum for message ID they didn’t have at compile time.
Another subtlety is that you can only run the structural CRC over the base part of the message - any message extensions don’t change the structural CRC or you end up breaking if sender and recipient have different subsets of extensions for a message.
The application of this idea for UAVCAN is complicated by the lack of a CRC on single frame messages. It still would be nice for multi-frame however, and would provide a lot of protection against projects not keeping their DSDL in sync.
i’m not really sure what you’re asking …
we use the CAN node ID as part of device IDs, and we track it in our DNA server (we have our own DNA implementation, we don’t use the libuavcan one). We have arming checks for duplicates discovered by the DNA server, and we persistently store the DNA database as part of hal.storage.
For AP_Periph, we default to CAN_NODE=0 parameter, meaning “use DNA”. Users can change the parameter on the node to get a fixed node ID.
I get the feeling I missed the point of your question though
in the short term we wouldn’t, as it would just waste flash space. If someone can show me a real benefit to users of implementing it then we could add it once the kinks in the config system are all sorted out.
We take a very pragmatic approach in ArduPilot. We will support just about anything if it really does benefit users and the implementation/maintenance cost is not horrific. We have a bunch of different CAN protocols now, added on the basis that they are useful to someone.
I like this reserved bit + semantic_id directive approach. It preserves the flexibility and capability of v1 while also allowing for a simple and clean solution that can be defined in DSDL and checked at compile time; in my opinion it preserves many of the benefits v0 had while also allowing users to take advantage of v1’s flexibility. Such a solution can be implemented into the tooling fairly simply, and the modification involved to the UAVCANv1 standard to accommodate such changes is largely uninvasive as far as I can see. This solution has my full support, for what it’s worth.
If you don’t particularly care about which reserved bit we’re using, perhaps one of these would be more preferable? They’re currently completely unused (ignored by the specification).
thanks for checking if they are used. I chose 23 as it is marked as an incompatible bit (ie. don’t process pkt if its not set to 1). Using 21 or 22 would be fine as long as there aren’t v1 implementation out there that will be unhappy about the packets sent by this semantic_id approach. I suspect it’s early enough in the v1 release process that we can re-purpose one of those bits, but Pavel may know of deployments that would care.
I think you understand my proposal correctly, yes. I am wary of using terms like “convention” or “guarantee” at this point though because our environment is not that well formalized so the difference is not clear-cut, which, I think, matters.
Say, in the common usage scenario, v0 ensures that you don’t accidentally network-cast (nice term by the way) your data to a wrong type, so that’s safe. But it doesn’t provide stronger guarantees than v1 does regarding the instance-ID: say, if you were to misidentify the feed from sensor X as sensor Y, drastic consequences may result despite the data being of the same type (e.g., you could have two magnetometers oriented differently). The instance identification is implemented not at the compile time (unlike data type ID) but at the configuration time (by assigning the node-ID and/or sensor-ID). Following your terminology, it would be a “convention”, not a “guarantee”. Am I reading you correctly?
You seem to be accepting that as safe with the help of your arming checks that ensure that the node-IDs are unique within the system. I don’t think this is fundamentally different from v1, where similar checks can be easily automated as well. Let me summarize so that you could double-check that I really understand where you are coming from:
Property checked at…
v0
v1
Data type
compile-time
configuration-time
Data semantics
N/A
configuration-time
Service instance
configuration-time
configuration-time
In order to implement a safe service client, the full triple is required. For instance, using the magnetometer example, we need to know:
the type (is it a magnetic field strength type?)
the semantics (is this magnetic field reading intended for navigation or it’s coming from the payload (like gimbal)?)
the instance (is it the sensor A, which is oriented (0,180,0), or sensor B, which is oriented (90,90,0)?)
v0 statically ensures (type+semantics) but not instance. v1 statically ensures none. Both have the potential for misconfiguration. Admittedly, v1 contains two more dimensions to be misconfigured, but it is not fundamentally different.
Just like your PnP node-ID allocator can take care of these checks for many use cases, my port autoconfiguration method can offer equivalent user experience (actually better user experience since it can automate more cases as I wrote earlier).
We agree on all of the points listed. I think I wasn’t clear enough, let me correct that.
New functionality certainly won’t appear magically so:
someone needs to design network services to model it (which usually but not always involves crafting new data types);
someone needs to write code to implement these services;
someone needs to configure nodes so that they are properly connected to said services (this means setting port-IDs).
The difference is that per SOA, v1 allows you to extensively reuse network services without the need to patch the network with ad-hoc specialized interfaces (types). This is the critical advantage that is necessary to make UAVCAN long-term viable and usable outside of small drones.
Are you trying to smuggle data type IDs back into the Spec (disguised under a different name)? I think you are.
I think it is a bad (and quite complex) proposal because it perpetuates the deficiencies of v0 that I am not ready to tolerate. You already know my position on this. We did not yet exhaust our options in idiomatic v1 so let’s put your proposal aside for now.
Very true. I consider this as one of the fundamental advantages of UAVCAN over higher-level solutions like DDS.
The lack of a single-frame CRC is the lesser of the problems here. The really critical problem is that UAVCAN has to rely on polymorphism to make advanced and extensible interfaces possible, which is incompatible with rigid hashing. This is a known issue but it cannot be addressed with a simple CRC, which is why it was removed. More on this:
not even close.
The sensor_id in 1002.MagneticFieldStrength2.uavcan is in the packet. First the v0 type safety guarantees you are getting a 1002.MagneticFieldStrength2.uavcan packet, then directly inside that packet you have the sensor_id.
In v1 the “configuration” based check is distributed. You don’t get information with each packet on either the type or the instance ID.
The big distinction I am making is that type safety needs to be in the packet.
you know better that that. Stop trying to dress this up as something it’s not.
again, totally different things. The consequences of the DNA being broken and ending up with two nodes having the same ID is fairly benign. We don’t end up casting baro data to compass data.
Calling it ad-hoc when it isn’t the design you like doesn’t make it bad. Your SOA approach is just as ad-hoc as adding a message to v0.
yes. i’m trying to do whatever it takes to keep UAVCAN viable. That means finding some way past the blockage formed by your ideas on what makes a good protocol for sensors on CAN in UAVs.
The hand waving approach to type safety that you are advocating in v1 just doesn’t cut it. Type safety really matters. You can still compose packets all you like.
then come up with something that has compile time guaranteed type safety and can work with a network analyser like we have in v0.
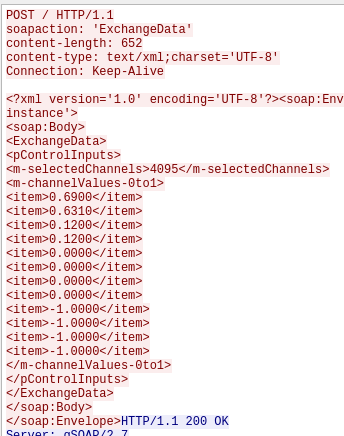
SOA and type safety are not incompatible, you just need to have the semantic type in the packet. The SOAP protocol (which is the poster child for SOA) does this all the time, by putting the string request type at the top of every request. Here is a typical SOAP request (this is the SOAP FlightAxis protocol used for connecting flight controllers to the RealFlight simulator):
see the “soapaction” field? That is a semantic ID. This is normal in SOAP. Why? Because eliminating the semantic type in packets is a really really bad idea.
See SOAP spec:
The hash can be on the structure only, not the field names. It is meant to protect against the evolution of the DSDL within two different projects (eg. PX4 and ArduPilot) that want to be able to communicate reliably. It has absolutely nothing to do with polymorphism.
At this point in the conversation, I am becoming increasingly cautious to take sides in this conversation. As such, I’m going to try to ignore my own opinion on this and ask questions (to everyone) as a 3rd party.
This worries me, because if AP_Periph does not support the flexible approach, it would harm interoperability in other domains.
It is different - from what I can see, the failure modes caused by not ensuring type or semantics are far more drastic than instance IDs. It is also easier to figure out instance IDs automatically if you are 100% sure the type and semantics are correct.
Yes he is, but in a non-intrusive fashion. For that specific reason, I support Andrew’s idea in this case. If that bit is kept at 1, network services can carry on as if nothing was ever hard-coded.
Upon thinking more, I have another concern with this proposal (although originally I really liked it): in order to support the fixed-id use case, messages would need to be duplicated for each specific type and semantic meaning. This would conflict with the benefits of having non-fixed port IDs in the first place.
This is the one point that is still underemphasized despite reiteration - some optimization-related sacrifices must be made in order to make UAVCAN applicable to a wider domain across a longer time scale. There are some sacrifices - a direct consequence of designing services that are applicable to a wider scope than what is used in the present day - but I believe these sacrifices can be overcome and are worth it in the long run, but @tridge may not agree.
What I don’t understand is why? Maybe I’m missing something extremely obvious but I am yet to come across an example where an auto configurator would break down.
I think you misinterpreted what Pavel is saying. Ad-hoc is not a good word here; specialized is more accurate. He is saying that he is opposed to any overly domain or equipment-specialized messages because such messages limit the reusability and applicable scope of any network service across future use cases and the broader UAVCANv1 ecosystem.
There are two completely independent problems here, so let’s please treat them as such.
Compile time guaranteed type safety:
Yes, you are correct. The current proposal does not guarantee this. It is unfortunate but I still can’t see any actual problems occurring as a result of this.
Network analysis
It will be some more time before I have a prototype, but this can definitely be arranged if an application layer bus monitor (such as post-mortem playback in Yukon) has context about port IDs. This can be achieved by looking at the same registers that the ID allocator does, or by just asking the allocator directly. Keep in mind that these configurations are reasonably static, so once exported (or manually input, even though this is quite cumbersome) once, they apply to any future log.
As iterated before, the concern in general is not that we will run out of IDs. I think this has been stated before. I hope you understand the following already, @tridge, but I will state it again: my main problem with introducing standardized semantic IDs (other than the service classes I already proposed for UDRAL, which are serialized at a packet level) is that it is limited to only those use cases that the original standards designer can think up, or at the very least, introduces (non)-intentional biases towards such semantics. This restricts integrators from using these services in a semantic configuration that is not envisioned by the original standards designer.
I am satisfied with the reserved bit toggle because these restrictions can be turned off, no questions asked, by a network service provider or consumer - but they are still there for those who want them. Pavel is of the opinion that he doesn’t even want such semantic associations anywhere in the standard because they have the potential to encourage bad practices, which is why he suggested enforcing it at the autopilot ecosystem level. I don’t agree with that solution because it doesn’t solve the original problems you intended it to, which is static type and semantic safety across the entire UDRAL ecosystem.
@semantic_id 2
uint3 instance
int16 field_mgauss[3] # in milliGauss
it contains a magnetic field. The recipient needs to know it contains a magnetic field (and the units) to make any use of it. How can you “re use” this as anything other than a magnetic field? Changing the subject ID you send on doesn’t magically make this a gyro rate or an acceleration.
You can combine this magnetic field message with any other number of messages to achieve whatever goals you like - so it is composable. When you do that the bits in this message still represent a magnetic field.
nope. That magnetic field will always be a magnetic field no matter how much you play with service ID assignments. There is no applicability of this data outside of it being a magnetic field.
The semantic_id doesn’t force you to use this field in a particular way - you can use magnetic fields in lots of different ways. What you can’t sanely do is use it as an air pressure or a gyro rate. That is just nonsense.
The whole idea that we will turn a message that has a specific set of semantics into something grander through removing the semantic type is just rubbish.
strong typing is one of the bedrocks of reliable computing. It is why we use classes, types etc in languages like C++. We want to guarantee that we don’t pass a magnetic field into a piece of code expecting a pressure. Languages that guarantee that at compile time are preferred as they lead to more robust systems and less aircraft ending up in pieces on the ground due to bugs.
The network equivalent of that is putting an ID in each packet saying what the semantic type of the packet is. That is not a difficult concept, and it is the way it has been done for decades in network protocols because it is simple and it is robust. It is also done in SOA systems and is completely compatible with that.
You could have dynamic address assignment and still have semantic IDs in packets. We have that in v0 with the DNA dynamic address assignment. We could add another layer of ports in between and still keep the semantic type ID somewhere else in the packet (that is what my first CANDevices proposal did). I don’t think that extra layer of runtime assigned port IDs actually adds any value, but it is possible.
Yes. I think you misread my point again. Of course that type will always be a magnetic field. However, it may not always be a magnetic field for use in a UAV for heading estimation. Type != semantic usage. This is also the reason I am strongly in favor of enforcing SI units and semantic splitting of messages, as they make the same data applicable to more use cases.
I am not saying it is. I understand it perfectly. I am saying that it puts an implicit boundary on the subset of applications that can use the message by making associations between type and semantic usage where there should not be any, at the standards level.
the semantic_id just says its a magnetic field. It does not say you have to use it for heading. That is up to the consumer of the data.
In that case, I find this somewhat acceptable. Not ideal by any stretch in my mind, but acceptable.
However, are you content with just solving the type safety? What about the semantic usage and instance ID safety problem (using the gimbal’s magnetometer for vehicle heading reference)?
Pavel may not find this acceptable, but I will let him make his own conclusions.
I like this. My only issue is that when there are two ways to do something (the Magnetometer message versus publishing MagneticField on a topic) it becomes hard to enforce either (or compliance to both). @dagar Do you think this may be a problem?
what problem? The mag calibration data can be associated with an ID formed of the CAN bus number and the instance number. Where is the problem?
well, gimbals don’t usually have a magnetometer. If you did add a mag to the rotating part of the gimbal (why would you do that?!) then the user configuring the vehicle would need to know that this is a non-useful magnetometer for flight control. We’d use the COMPASS_PRIO IDs in ArduPilot to ensure we use sane magnetometers plus the compass calibration process would fail, as the fitness check we do during calibration would fail, as the data doesn’t map via an elliptical transform onto a sprehe within the allowable range of offsets, diagonals and off-diagonals that we use in ArduPilot.
but really, why is this example in any way useful? In the real world what we’d do is have a wiki page telling users to disable the mag on this badly designed gimbal and we’d contact the vendor telling them to stop selling silly devices.
None of this detracts from having a semantic_id in the magnetometer packet saying that the data is a magnetic field. That is essential data.
My only issue is that when there are two ways to do something (the Magnetometer message versus publishing MagneticField on a topic) it becomes hard to enforce either (or compliance to both).
We can have some kind of separation (similar to parts of DS015).
This is where I start feeling uncomfortable. It’s not that there is no purpose; it’s that the purpose may not be immediately obvious in the field of small unmanned aerial vehicles in the present day. I would think that to claim to support UDRAL, a UAVCAN node would at least need to acknowledge the existence of other domains and use cases.
We could, but would it suffice to determine types in the packet (perhaps with the reserved bit or perhaps in the payload) and leave semantics up to configuration?