@dagar and @tridge are correctly pointing out that that non-fixed port-ID assignment is prone to a particular failure mode where multiple nodes interact with the same subject under incompatible assumptions about its semantics. This is an intentional design decision that is made explicit in Specification, where it simply hands off this problem to the implementer:

UAVCAN v0 used to offer a somewhat limited solution to this problem by seeding the multi-frame transfer-CRC with some function of the identity of the data type. While it worked well in simple scenarios, it breaks when type polymorphism, intentional network casting, or differently named data types are involved, so it had to be removed from v1. Here is a relevant excerpt from the Guide:
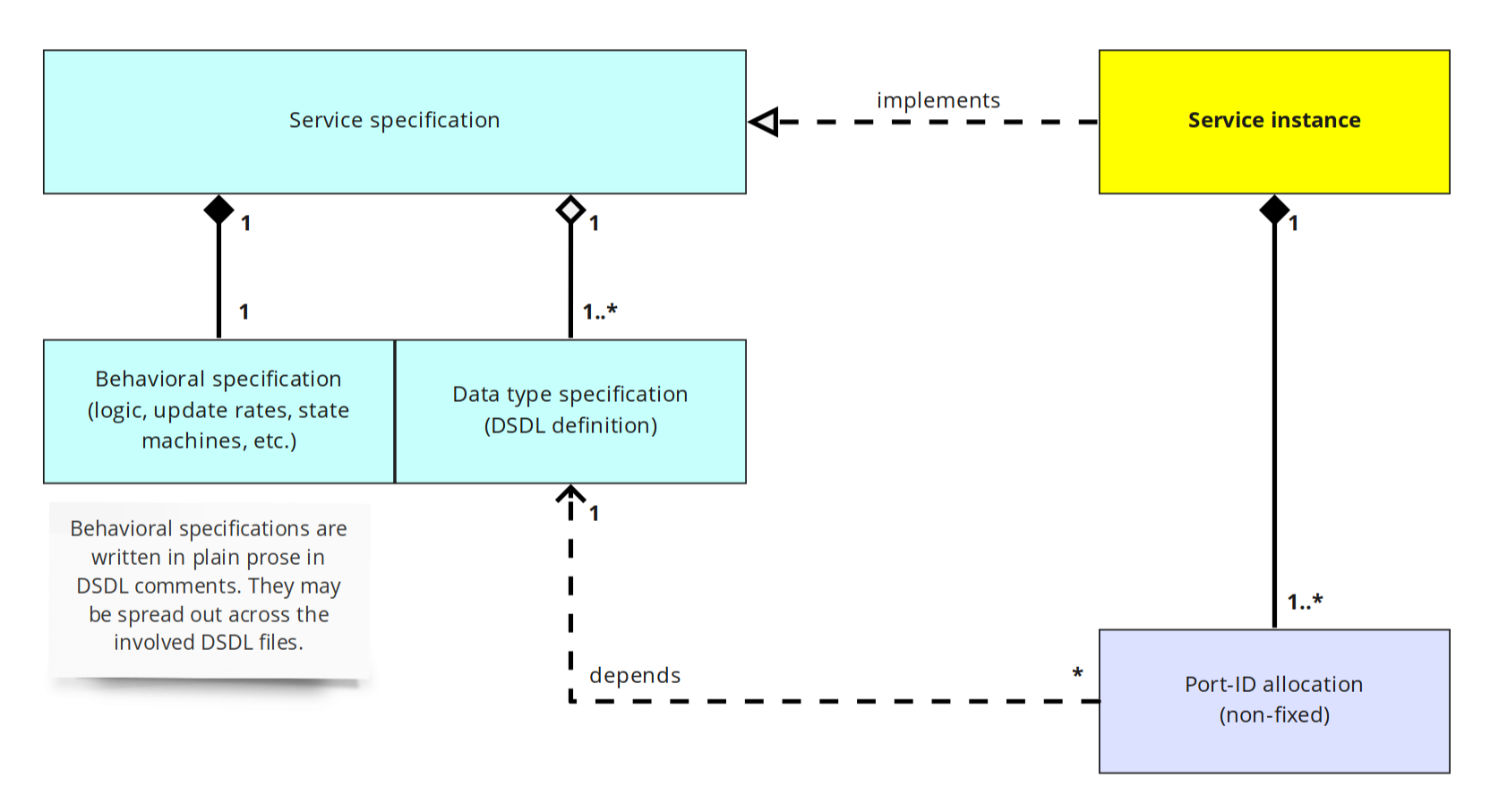
[A] network service specification is an abstract blueprint, focused on high-level behaviors and contracts that do not define the means of its implementation. Implementing the said behaviors and contracts such that they become available to consumers is referred to as service instantiation. Instantiating a service necessarily involves assigning its subjects and UAVCAN-services certain specific port-identifiers at the discretion of the implementer (for example, configuring an air data computer of an aircraft to publish its estimates as defined by the air data service contract over specific subject-IDs chosen by the integrator).
Excepting special use cases, the port-ID assignment is necessarily removed from the scope of service specification because its inclusion would render the service inherently less composable and less reusable, and additionally forcing the service designer to decide in advance that there should be at most one instance of the said service per network. While it is possible to embed the means of instance identification into the service contract itself (for example, by extending the data types with a numerical instance identifier like it is sometimes done in DDS keyed topics), this practice is ill-advised because it constitutes a leaky abstraction that couples the service instance identification with its domain objects. Continuing with the air data computer (ADC) example, one could assume that multiple ADC may be differentiated by a dedicated numerical ID, but this would come at a cost of polluting the application data with unrelated implementation support details and forcing the service designer to determine the allowed composition strategies.
[…]
Even though there are costs in the form of the new failure mode, they are justified by the significantly expanded capabilities of the protocol. I am providing this context to help the members understand the design of v1; keep in mind that the discussion of this specific design aspect, or the design of UAVCAN v1 in general, is outside of the scope of this SIG.
This issue was first brought up by Andrew in the now-closed thread on DS-015:
I actually wrote a comprehensive response to that post that was never published because the decision to terminate DS-015 was made just before I could post it. Let me copy-paste the relevant bit from that unpublished response here:
There is another option that I did not mention in my original response, but it was recalled by @dagar — the standard subject type register, which is actually present in the (now defunct) DS-015 demos I shared earlier:
From the pure functionality standpoint, I think that these three measures should be sufficient to address the problem. The UDRAL standard (do we agree on this name, by the way?) should probably make it a requirement that the uavcan.PORT_KIND.PORT_NAME.type and uavcan.node.cookie registers are mandatory for all nodes.
I want to reiterate once again that adding a sensor type-ID field to every message is deadly for the architecture of the distributed system for reasons explained in the Guide.


{kind=link}