The proposed JSON schema is not good: it fails to distinguish between static type information and runtime defined values. I propose an alternative schema which closely follows the DSDL data model.
- Primitive values are represented in JSON as-is. For example,
bool is just true or false, a floating point number is just a JSON float literal.
- Void-typed values are not represented at all.
- Array values are represented as JSON arrays.
- Composite values are represented as JSON dicts, where each field has a dedicated entry indexed by name. Additionally, a special entry under the key
_type_ is introduced, which contains the name and version of the data type of the current composite. See example below.
This is for Heartbeat:
{
"_type_": ["uavcan.node.Heartbeat", 1, 0],
"uptime": 123456,
"health": 2,
"mode": 0,
"vendor_specific_status_code": 12345
}
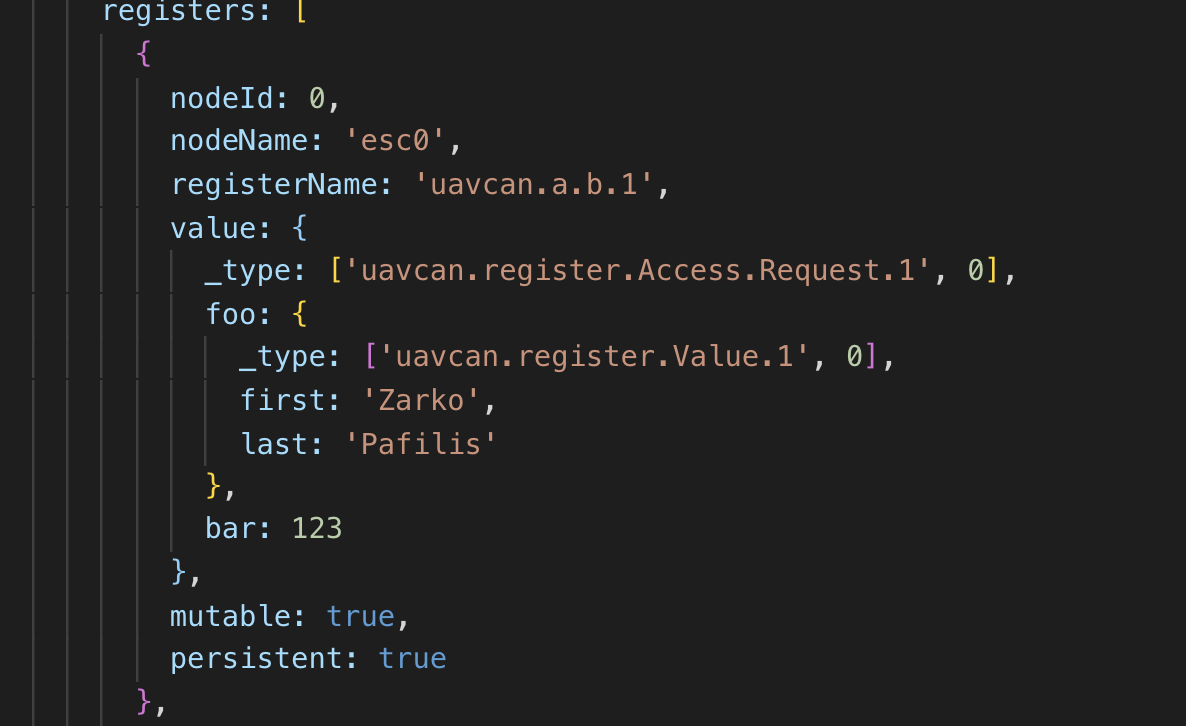
This complex example is for register access request (name reads hello world; DSDL does not differentiate between arrays of uint8 and UTF8 text):
{
"_type_": ["uavcan.register.Access.Request", 1, 0],
"name": {
"_type_": ["uavcan.register.Name", 1, 0],
"name": [104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
},
"value": {
"_type_": ["uavcan.register.Value", 1, 0],
"real32": {
"_type_": ["uavcan.primitive.array.Real32", 1, 0],
"value": [123.456]
}
}
}
The data type uavcan.register.Access.Request actually does not exist, there is only uavcan.register.Access which has a request schema definition.
This representation does not require us to transfer constant values over the REST interface, which is good because constant values never change. The front-end can request data type definition as necessary and cache the response forever since data type definitions never change (unless the major version number is zero — those may change and so they shouldn’t be cached or the cache should expire quickly). Data types can be modeled like in PyDSDL, by naive translation of the Python data structures into JSON. For example:
{
"full_name": "uavcan.register.Access",
"version": [1, 0],
"is_service": true,
"fixed_port_id": 384,
"constants": {},
"fields": {
"request": {
"type": ["uavcan.register.Access.Request", 1, 0],
},
"response": {
"type": ["uavcan.register.Access.Response", 1, 0],
}
}
}
{
"full_name": "uavcan.register.Access.Request",
"version": [1, 0],
"constants": {
"EXAMPLE_CONSTANT": {
"type": "saturated float64",
"value": 123.456
}
},
"fields": {
"name": {
"type": ["uavcan.register.Name", 1, 0]
},
"foo": {
"type": ["uavcan.register.Value", 1, 0]
},
"bar": {
"type": "saturated int32[<=123]"
}
}
}
Such representations can be constructed trivially with the help of PyDSDL.