Regardless of how many fields one can append to an existing message, at some point the technical debt accumulating from such compatibility-preserving extensions would make evolution of the type difficult. From that assumption follows that occasional breaking changes are unavoidable; given that, it should be possible to find a sensible balance between the probability of premature breakage and the amount of reserved space. Generalizing from my experience, I see that lack of particular fields is rarely a problem; generally, when an existing interface requires change, its structure ends up being affected significantly enough to make preservation of bit compatibility impossible or at least hard to ensure. I realize that this might be different in MAVLink considering that it is designed to address different objectives.
We have the major version number update policy to deal with such breaking changes on a per-type basis.
The problem with real-time systems and message trimming is that a real-time network has to guarantee that a specific performance goal is met under all operating conditions. If a message is changing length depending on its contents, the network would have to be designed for the worst case, that is, untrimmed message size. The outcome is that the bandwidth released by trimming would not be usable for real-time processes anyway.
The above is not to say that trimming and other non-deterministic methods are useless. After all, we have variable-length data structures in UAVCAN – arrays and tagged unions. I perceive that given the real-time considerations, the utility of trimming compared to the resulting complication of the transport is insignificant.
If you think this is misguided, we could discuss this in-depth and see if it gets us to any interesting decisions.
The fact that Specification is withdrawing from managing high-level application-specific data types such as GNSS messages doesn’t mean that they are not going to be managed at all. We have the dedicated repository for public regulated data types at GitHub - OpenCyphal/public_regulated_data_types: Regulated DSDL definitions for Cyphal (standard and third-party), where any vendor is free to propose a new data type. Each vendor has a dedicated namespace. Users and implementers of UAVCAN are advised to rely on existing data type definitions published in that repo instead of reinventing the wheel. UAVCAN maintainers still decide which types should be accepted into the repository and which should not be, which sets some minimal quality bar, allowing us to combine the expertise of UAVCAN maintainers in designing UAVCAN interfaces with the expertise of vendors in their respective application domain. I think this approach is optimal or close to it because it allows us to combine the best of the two.
You understood the part about the low bit count correctly.
UAVCAN v0 used to have the concept of “data type ID”, it is gone from v1. In v1, a data type is identified by its name only. When one needs to establish communication over UAVCAN by publishing a stream of messages of a particular type, the stream is assigned a numerical identifier called “subject-ID” (as in, the subject of a message). Subscribers to the stream expect it to be of a particular type; it is up to the integrator to enforce the correct type matching.
There exists a very rare exception of data types where the subject-ID is defined by the data type designer; it is called “fixed subject-ID”. Normally, only the low-level types defined by the specification itself can benefit from a fixed subject-ID, for example, the Heartbeat message, the time synchronization message, log message, and most of the standard services.
Data types defined by vendors for use in closed ecosystems, such as within proprietary vehicular systems, also can benefit from fixed subject identifiers, because the scope and usage scenarios of data types defined for a closed ecosystem can be reasonably foreseen by the type designer.
Data types published in the public regulated data type repository are also allowed to use fixed subject identifiers; the ID conflicts are avoided simply because all of the definitions are managed in a centralized manner.
That’s it. A standalone vendor is simply banned from using fixed identifiers for their types if it is planned to be made public. Here, UAVCAN follows the same approach as DDS, CAN Kingdom, CANopen (assuming dynamic PDO mapping), or ROS: the syntax of a data type is entirely decoupled from its semantics.
A vendor releasing, say, an RTK unit, will have the following options:
- Use data types with fixed subject identifiers from the public regulated data type repository. Soon there will be application-specific data types for RTK, but they are unlikely to ever get a fixed subject-ID because it breaks the architecture of the protocol, so see the next option.
- Provide a configuration parameter, allowing the integrator to choose the subject-ID at the device integration time. This is the correct approach in this specific case.
You can find the discussion that led to the above decisions here if you are interested in the context: On standards and regulation
Understood. As I said, currently one can rename a type arbitrarily without affecting the compatibility. It’s important that the concept of compatibility is concerned only with the syntax of the data, that is, with the arrangement of its primitives, not with its purpose. This would break for the new experimental transports relying on the data type hash, but as I wrote already that is a matter of ongoing research and experimentation. I would like to explore the possibility of supporting polymorphism through the data type hash, it is not yet clear to me if there exist valid approaches.
A practical example is provided in section 3.8.3 of the specification, in the blue box at the end.
Speaking about the Fix types specifically, once Fix2 is released, the original Fix would be marked @deprecated. For a long while (the period depending on the typical design lifespan in the target industry), systems will be supporting both Fix and Fix2, then Fix will be removed from the data type set and vendors will cease to support it.
It’s complicated.
The short answer:
- If the toggle bit in the first frame of a transfer is zero, you are dealing with v0.
- If the toggle bit in the first frame of a transfer is one, you are dealing with v1.
The slightly longer answer requires a truth table. Each UAVCAN-over-CAN frame has a tail byte. The tail byte contains the metadata necessary for multi-frame transfer reassembly and deduplication (because the CAN bus may spuriously duplicate frames, but this is outside of the scope right now).
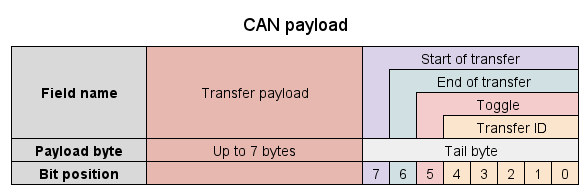
The figure is taken from the v0 specification, in v1 it is identical except that the number of payload bytes can be up to 63.
- Start of transfer – this flag is set if the current frame is the first frame of a transfer.
- End of transfer – this flag is set if the current frame is the last frame of a transfer. For single-frame transfers, both start and end are set.
- Toggle – this flag alternates between the frames in the same transfer. Its original state, that is, when the start flag is set, encodes the version of UAVCAN.
| Start of transfer | End of transfer | Toggle | Protocol version |
|---|---|---|---|
| 1 | x | 0 | v0 |
| 1 | x | 1 | v1 |
| 0 | x | x | ? |
See? To support multi-frame transfers in a dual-stack application, you will have to maintain an additional state on a per-transfer basis. It’s not difficult, just a minor inconvenience. Frames belonging to the same transfer share the same CAN ID value, so that helps (this is a hard requirement in both versions).
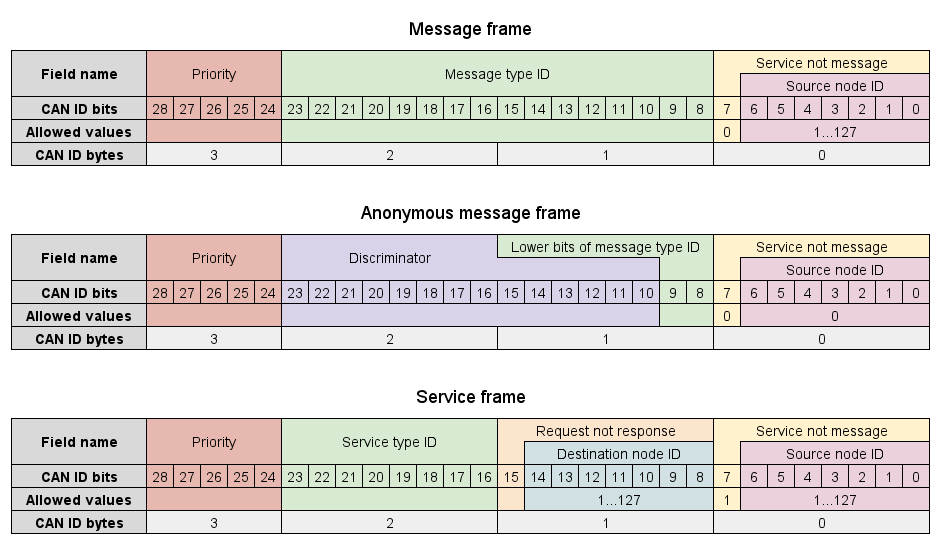
The full answer requires a reminder that in a CAN bus, nodes are not allowed to publish CAN frames with different payloads under the same CAN ID simultaneously. Within the same UAVCAN version, this is not a problem because the CAN ID differentiation is enforced by the node-ID embedded into it. When we share the same bus between v0 and v1, we arrive at the complication. Here is the ID structure defined for v0:
And here is v1:
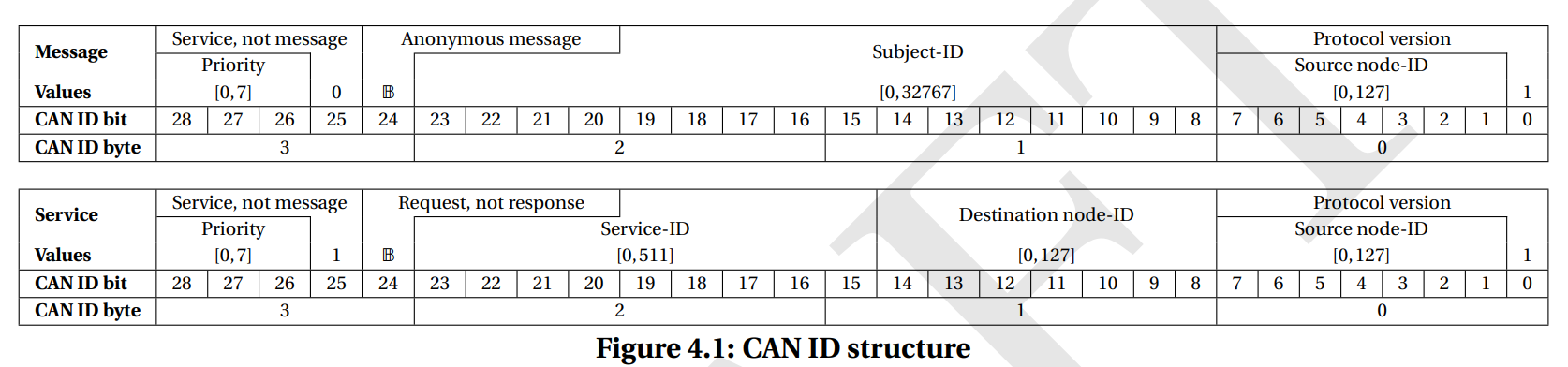
It is easy to see that due to the source node-ID being shifted one bit to the left (which was unavoidable because we needed to reserve the least significant bit for protocol version, to avoid having this issue in the future), the sets of emitted CAN ID for nodes under different node-ID and different protocol versions intersect. The intersection is small and it does not make a difference for a typical light UAV where UAVCAN networks are simple, but it might be a problem for a safety-critical deployment unless special measures are taken to avoid collisions.
A robust solution is to ensure that v0 nodes are assigned even node-ID values, not odd – this works because a v1 node always sets the version bit, thus ensuring that CAN ID sets do not intersect. Alternatively, the differentiation could be enforced via the first three priority bits, for example all even priority values could be banned for v1 nodes (leaving only 1, 3, 5, 7), and for v0 nodes the following would be prohibited: 0, 1, 2, 3, 8, 9, 10, 11, 16, 17, 18, 19, 24, 25, 26, 27.
However, observe that for the problem to actually have an effect on the application, all other bits of the CAN ID will have to be identical, which is highly unlikely. I expect that ArduPilot deployments may simply ignore the problem.