DSDL definitions in their original form are hard to read by humans which impedes the adoption of UAVCAN and DS-015. Yet DSDL is sufficient for describing behaviors of a distributed computing system (DCS) without the need to resort to additional means of documentation (that would run the risk of divergence). It is therefore desirable to make DSDL specifications more approachable for humans without changing the language or specifications themselves.
To illustrate, suppose that you want to implement the servo network service as defined by the DS-015 standard. You go to the service definition file:
…whereat you see that to fully grasp what’s in there you need to do quite a bit of jumping around the files in the repo that are not even syntax-highlighted. This is a serious obstacle if you are just evaluating whether UAVCAN/DS-015 are the right solutions for you.
We, therefore, need to come up with a better presentation of DSDL definitions. The solution I propose is to define an additional target for Nunavut that yields HTML pages with documentation per DSDL root namespace. But before we get to that, there is one blocker to take care of:
Exposing comments in the AST constructed by PyDSDL
PyDSDL is the DSDL processing front-end used by Nunavut. It accepts a root namespace and yields a well-annotated AST based on that. Currently, PyDSDL discards comments, so we need to change this behavior:
The AST should be extended with two extra entities — composite type documentation and attribute documentation:
# This header comment is the documentation for this composite type.
# It may span an arbitrary number of lines and is terminated by the first non-comment line.
float64[4] foo # This is an attribute comment for field "foo"
bool bar
# This is an attribute comment for field "bar".
# It spans multiple lines.
# This comment is not attached to anything because it follows a blank line, so it is dropped.
uavcan.primitive.Empty.1.0 baz # This is for "baz".
# And this one is for "baz", too.
---
# This comment is attached to the response section.
void64 # This comment is for the padding field.
int64 MATH_PI = 4
# This is the best known approximation of Pi.
The composite type documentation is to be exposed via new property doc:str on pydsdl.CompositeType. A similar property should be added to pydsdl.Attribute.
Comments can be extracted from the source file by adding a new node handler visit_comment() to the internal class pydsdl.parser._ParseTreeProcessor.
The leading # and the space after it (if present) should be removed.
Once this is done, we can proceed to the second part.
Emitting HTML using Nunavut
Proper templates provided, Nunavut can map a DSDL root namespace to a fully-static website (which may be contained in one or several HTML files, perhaps with additional files for styles, scripts, or other resources; in the interest of portability it might be better to bundle everything into one large file). It is important to rely on a web-compatible format because we can’t require the user to download any artifacts to be able to explore DSDL.
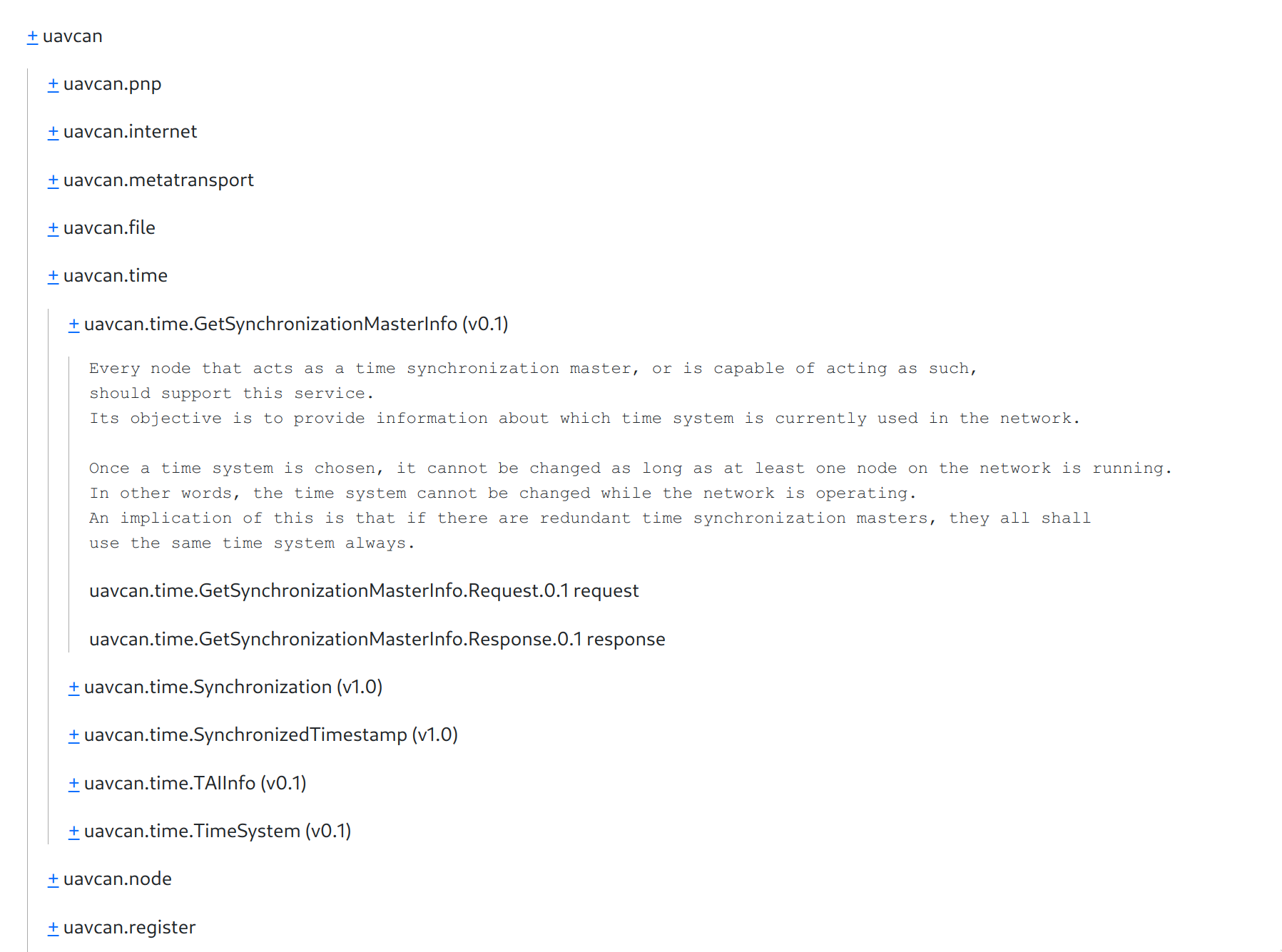
The view should be similar to a directory tree. Take the standard root namespace uavcan:
- uavcan
+ diagnostic
+ file
+ internet
+ metatransport
+ node
+ pnp
+ primitive
+ register
+ si
+ time
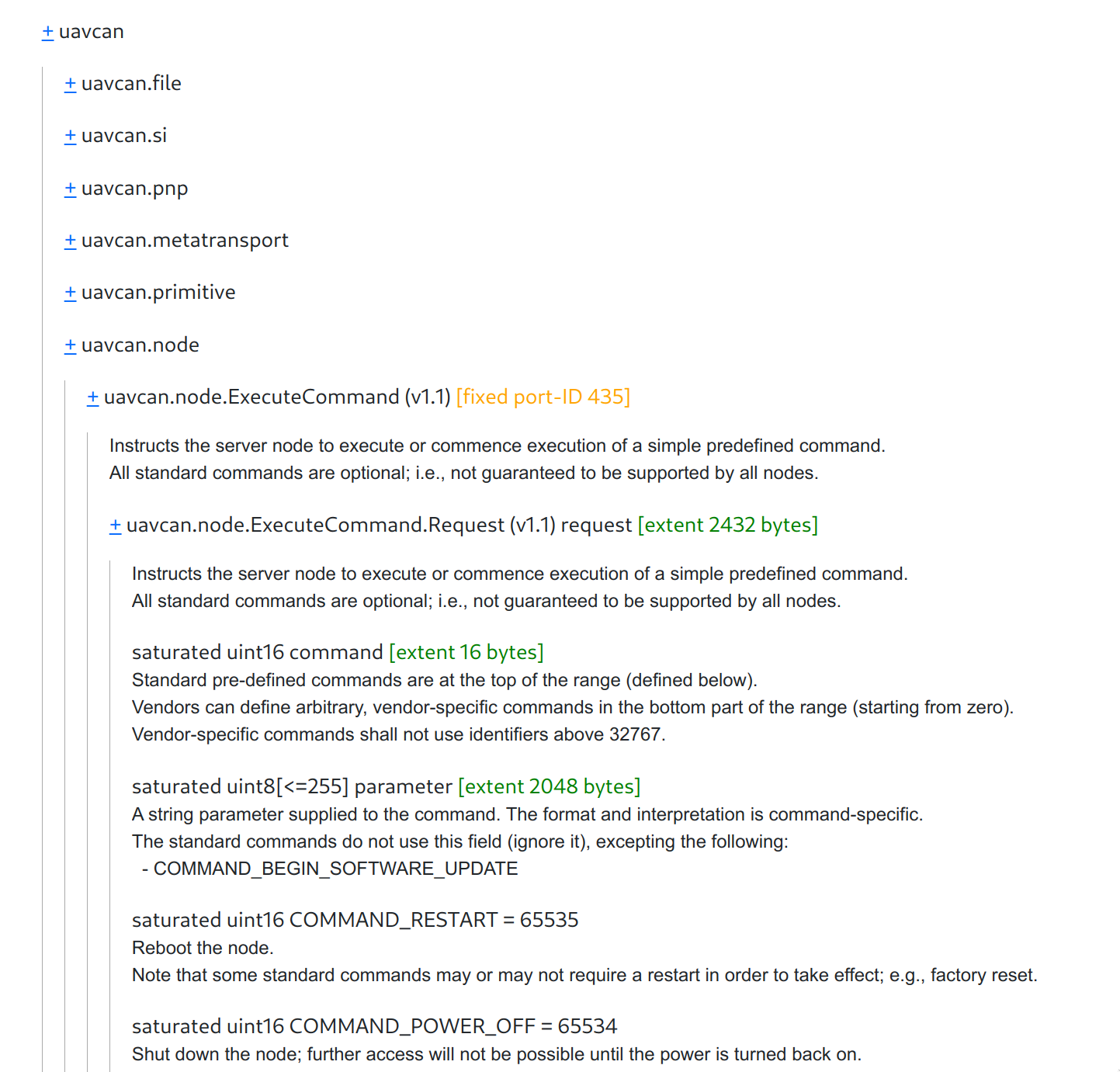
The user clicks on a namespace and it expands in-place. The same goes for data type definitions, this is important:
- uavcan
- diagnostic
+ Record.1.0 [fixed subject-ID 8184, extent 300 bytes]
- Record.1.1 [fixed subject-ID 8184, extent 300 bytes]
Generic human-readable text message for logging and displaying purposes.
Generally, it should be published at the lowest priority level.
+ uavcan.time.SynchronizedTimestamp.1.0 timestamp
Optional timestamp in the network-synchronized time system; zero if undefined.
The timestamp value conveys the exact moment when the reported event took place.
+ Severity.1.0 severity
uint8[<256] text
Message text.
Normally, messages should be kept as short as possible, especially those of high severity.
+ Severity.1.0
+ file
+ internet
+ metatransport
+ node
+ pnp
+ primitive
+ register
+ si
+ time
The text should be syntax-highlighted but it does not need to replicate the source token-by-token (it is not even possible because the AST does not contain the required information). It is easier to re-generate the text by simply invoking __str__() on each attribute and adding the docs around them:
>>> import pydsdl
>>> composites = pydsdl.read_namespace('public_regulated_data_types/uavcan')
>>> str(composites[1].attributes[2])
'saturated uint8[<=112] text'
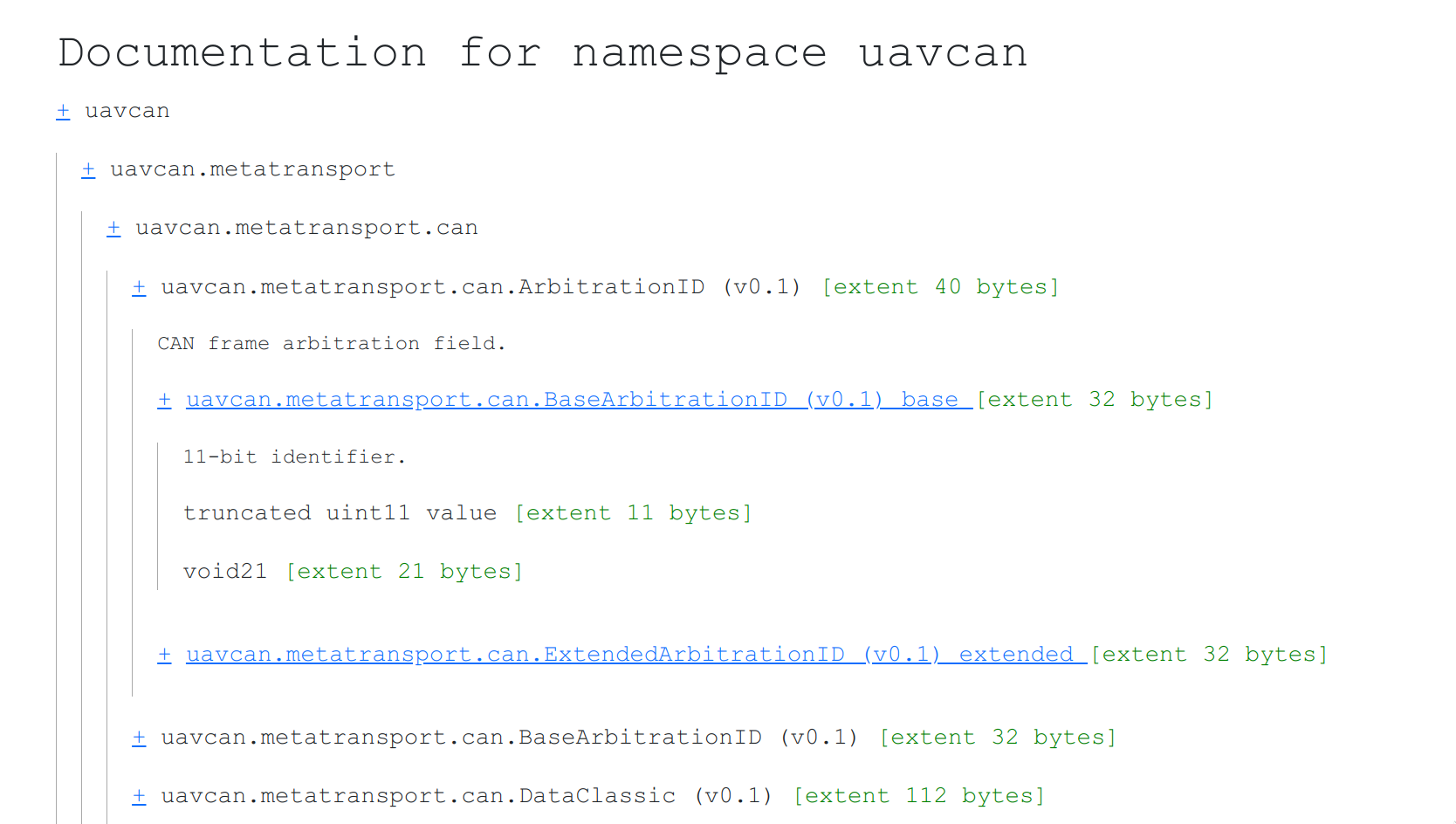
The user may click any attribute inside a composite type and it would expand in-place in the same manner. Another kind of click (with a modifier key like shift+click or using a dedicated button) should take the user directly to the definition of the attribute’s type instead of unfurling it in-place.
Hovering over a field, type, or namespace should display its contents along with key information like size but without doc comments in a quick pop-up.
PyDSDL provides the offset information per field; it should be displayed next to the field to simplify manual serialization and to keep the user aware of the data footprint.
Many doc comments contain references to other data types. They lack any special formatting but full data type names are sufficiently unique to unambiguously detect them in text as-is. For example:
Notice the reference to reg.drone.physics.kinematics.translation.Velocity1VarTs. The version number is not given, which means that the latest one is implied (v0.1 in this case). Such references should be automatically highlighted as clickable links. There may also be links to namespaces (with or without the trailing .*:
This fragment should take the user to the namespace reg.drone.service.actuator.common.sp.
Due to the fact that Nunavut is unable to process more than one namespace at once, links to foreign root namespaces would necessarily navigate the user to a different generated site. If the generated site is compressed into a single HTML file the navigation would be trivial to implement since we know that an entity like reg.anything can be reached via URI like reg.html#anything.
There are special data type definitions that are used to document namespaces. They are named _ (single low line), one is shown above. Such data types need not be shown in the output but instead, their contents should be expanded directly under the corresponding namespace entry.
I think it is sensible to interpret the text of doc comments as Markdown to allow data type developers to construct more appealing documentation. It would require fixing the formatting across the public regulated data types repository but it is no big deal.
@bbworld1 Would you like to work on this? This is very high-priority right now (above Yukon) because it is perceived to be an adoption blocker.
@scottdixon Did I miss anything important?