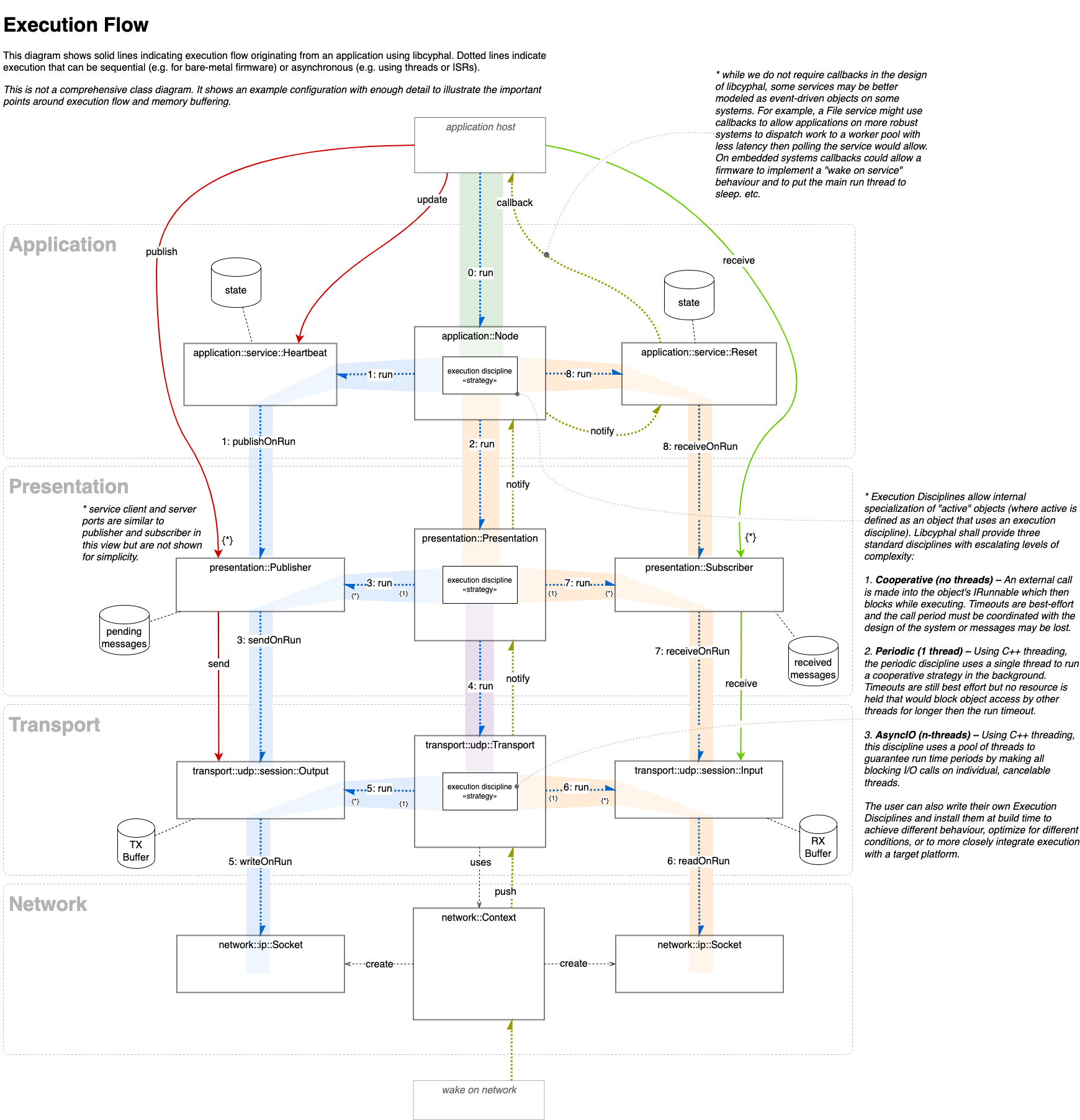
We are currently in the process of roughing out libcyphal APIs and will post a PR-as-design-review for these soon. Ahead of looking at that code this is the execution model we are proposing. Please review and comment:
2 Likes
Before reviewing this, I would like to ask if it is possible to see how this maps to Cyphal/CAN?
1 Like
I’m not sure CAN, or any transport, would be fundamentally different. We’re basically saying that all porting to libcyphal is done via a posix-like API surface so the network layer looks the same even on MCUs. After that I don’t see a strong reason to differentiate the architecture even if different execution disciplines may be more appropriate for some network layer implementations then others.


Do I understand correctly that sequential execution of the run methods under the Cooperative policy is effectively polling unless it is informed by optional notifications received from the lower layers (e.g., that a socket has become writable)? In practical terms, is it compatible with the simple design where a baremetal single-thread application polls the library at a high fixed frequency to let it make progress? Say, the logic of a certain motor controller may be implemented in two domains: the soft real-time domain that manages networking and runs in the main (and only) thread, and the hard real-time motor control loop that runs in the only ISR in the system (no other ISR’s allowed).
I sense that you wanted to avoid deep calls into the lower layers of the stack by using the presentation and session layers as buffers, such that when the application invokes send, the call stack does not extend to the bottom layers but instead a pending transmission intent is created and buffered, waiting for the execution of run. I find this interesting and reminiscent of the TX queue approach in lib*ards. One problem with this approach is that it may involve unnecessary data copying within the stack, as the lower layers cannot require the caller to ensure that the lifetime of the payload reference (e.g., a serialized message) exceeds the lifetime of the buffer, as it would be a major breach of abstraction. For libcanard/libudpard specifically, there is one very simple and equally dirty approach to avoid copying that was implemented by someone back when UAVCAN v0 was around: instead of staging the pending items at the next level of the stack, make a direct call to the bottom layers while the reference to the source data is still valid. This obviously creates complications with the control flow (e.g., blocking at the lower layers becomes a problem), but it does eliminate most of the copying, as the bottom layers can receive references to the original data buffer all the way at the top of the stack instead of being fed copies of the same buffer. This is relevant:
By the way, I have a decent implementation of an EDF scheduler in 300 lines of C++ (plus tests). The only dependency is Cavl, which we’re already familiar with through libcanard and libudpard.
I wonder if @aentinger has anything to add, considering his ongoing work on Ethernet support.
Do I have anything to add? No, not really. The “TDMA part” of 10BASE-T1S is abstracted in the PLCA (Physical Layer Collision Avoidance) which is part of the MAC-Layer (please don’t nail me on this, it is part on the layer bordering PHY/Data Link) - higher level layers don’t even see anything out-of-the ordinary, to them it looks like a 100BASE-TX/1000BASE-T/etc. default star topology Ethernet network.
So writing to it/reading from it resembles the default socket experience, you simply don’t notice 10BASE-T1S save for some additional configuration at initialization (number of network nodes, node id, burst mode being the most relevant ones).
General design feedback is hard for me to give, I can provide better feedback from seeing and running the code than from such a - admittedly very nicely drawn - graph. Or I would have to sit-down with @scottdixon in office at a whiteboard, but simply staring at the graph on my monitor ![]()
![]() .
.
A way around this is to use a “borrowed memory” model for serialization where the application layer first borrows a buffer from the presentation layer and uses this memory to serialize and then push for transmission. This allows us to abstract where the true ownership of this memory is and it can be something that we borrow all the way down to a DMA buffer (i.e. the application asks to borrow from the presentation which delegates to the transport which delegates to the network which is an abstraction around a DMA buffer for transmission).
But then the memory can be borrowed from the heap just as well, right? Either way some form of memory management would have to be implemented regardless of which component provides it.
That is correct. The most bare-metal example would be where you had enough DMA to buffer N messages and any attempt to borrow more than N buffers for serialization would result in the borrow method failing. Applications would have to handle this as a buffer overflow error returned from libcyphal. In posix systems a copy is unavoidable since there is no way (that I know of) to borrow memory from a posix queuing discipline. This means the application would be borrowing from a fixed process memory buffer that was flushed with each run of the tx execution discipline. It is possible to implement this in a way that makes the tx execution a no-op where one can be guaranteed that a call to the posix send does not block. The network layer implementer can make this choice without affecting the layers above.
This is neat but I want to call your attention to the fact that there is another case of copying that does not appear to be addressable with this admittedly clever plan of sourcing memory directly from the DMA buffer, and it occurs when the payload is copied from the application-provided buffer containing the source transfer payload (a serialized message) into the buffer allocated for the network frame (e.g., a CAN frame or a UDP datagram). If the stack were allowed to perform calls deep into the lowest layers of the protocol stack during transmission, then it would be possible to avoid copying the payload from the application buffer completely and instead operate on its views. Upon being enqueued for transmission, a network frame would be represented as a set of several fragments (like iov): the header, the payload fragment view, and the footer (depending on the protocol).
I am not actually saying that such direct deep calling is superior — I do see the obvious architectural issues that arise in this design — but it needs to be presented for completeness.