I should have done a better job outlining the current state of the art to back up my reasoning. Let me fix that now. Please bear with me while I re-introduce the basics.
Background
We can distinguish data representations between self-describing formats and non-self-describing ones, where “self-describability” means that encoded data contains the associated metadata that describes its semantics. A schema defines the semantics of data separate from the data itself, which is obviously a prerequisite for a non-self-describing format.
Practical formats are located somewhere on the spectrum of self-describability rather than being one of the extremes. Self-describability is commonly leveraged to allow identical data representations to be interpretable using different schema definitions as they evolve.
A popular approach to implementing self-describing binary formats is the so-called tag-length-value (TLV) encoding, where data items are prepended with discriminators describing the semantics and delimiting the items. Other approaches are also used; notably, non-TLV formats where the data is delimited using dedicated control symbols (this approach is used in virtually all human-readable text-based formats).
Just like with self-describability, TLV-encoded formats often include non-TLV artifacts where it makes sense and vice versa. For example, UBJSON or ASN.1’s indefinite length containers use special delimiting symbols instead of length prefixes to facilitate streaming.
One aspect of self-describing representations which is rarely considered in the literature and yet is relevant for highly predictable deterministic systems is the question of redundant states. In the interest of minimizing the state space of a safety-critical system, it is beneficial to eliminate redundant states from data representations, which implies that constructs that affect the serialized representation while not modifying its semantics (like self-description) should be avoided or minimized.
Another issue that is important for robust systems is that of canonical representations (forms). In this write-up, if the mapping from the set of serialized representations to the set of application object states is non-injective (i.e., different serialized representations may describe identical objects), we say that such encoding is non-canonical. Conversely, a canonical encoding yields injective mappings.
Pure canonical non-self-describing encodings are almost never used in practice because practical systems typically require their interfaces to be extensible. To make an interface extensible, one has to amend serialized representations with sufficient metadata that allows an agent that lacks the exactly matching schema definition to interpret the data.
Below I am going to provide a brief overview of several popular binary encoding standards to help everyone understand the position of UAVCAN DSDL compared to similar technologies. In the overview, attribution of properties like self-describability, TLV, etc. is done for the general case and it is recognized that most protocols include edge cases where they exhibit different properties.
ASN.1
Abstract Syntax Notation One is one of the oldest data serialization standards still in wide use today. It is distinguished by its wide scope and complexity. A cryptographic expert Bruce Schneier had the following to say on the subject:
The best-known TLV encoding is ASN.1, but it is incredibly complex and we shy away from it.
I am not aware of any application of ASN.1 in safety-critical systems, although it obviously doesn’t mean that there are none.
The ASN.1 standard (maintained by ITU) specifies an extremely capable schema language and a collection of data representation formats, both binary and text-based. Among the binary formats, the following two types are most commonly used:
-
Basic Encoding Rules (BER) – a self-describing non-canonical TLV encoding. There are also two commonly used canonical restricted versions of BER: CER (C – canonical) and DER (D – distinguished) which differ in a couple of inconsequential implementation details.
-
Packed Encoding Rules (PER) – a non-self-describing non-canonical non-TLV encoding. Being non-self-describing, the format relies on an external schema definition. A restricted canonical subset called CANONICAL-PER is also defined. Further, PER is differentiated between ALIGNED, where field boundaries are aligned with byte (octet) boundaries by means of implicit padding (note how this might lead to non-canonical representations unless the padding is well-characterized), and UNALIGNED, which behaves like UAVCAN DSDL by squeezing bits together without regard for byte boundaries. UNALIGNED PER is often referred to as UPER.
Here we are going to focus on PER because it is the closest to the core requirements of UAVCAN. The specification is defined in T-REC-X.691-201508-I!!PDF-E.pdf. Other aspects of ASN.1 are specified separately (all specs are freely available from ITU).
ASN.1 supports data type extensibility with the help of a dedicated extension marker ... which can be added in the field list of a type definition to indicate that more fields may be added in a future version. It is not possible to add the extension marker retroactively without violating wire compatibility. The marker works by inserting a special hidden field before the data type which indicates if any of the extension fields are present. When combined together with variable-length encoding, it leads to highly convoluted binary representations, which are hard to follow manually. This forces one to rely on automatic code generators which suffer from interoperability and correctness issues due to the complexity of the standard.
ASN.1 does not support data inheritance in the conventional sense, although it is possible to express structural subtyping in a manner similar to DSDL unless a TLV encoding is used (TLV makes data aliasing impossible due to its self-describing nature).
ASN.1, being an old standard, encodes multi-byte values in the big-endian order. Modern standards tend to prefer little-endian due to the prevalence of little-endian machines in the world. Some standards like OMG CDR even allow variable endianness (sender-defined), which reduces computational effort but is suboptimal for safety-critical systems due to the above-explained reasons of state-space minimization.
Consistently with the byte order, the bit order is big-endian; that is, MSb has the lowest ordinal.
Let’s examine a simple demo. Here is an ASN.1 definition where Foo1 is to be considered the root type that includes a nested item Baz:
Foo DEFINITIONS ::= BEGIN
Baz ::= SEQUENCE {
qux INTEGER(0..65535)
}
Foo1 ::= SEQUENCE {
foo INTEGER(0..65535),
bar Baz,
msg VisibleString
}
END
We serialize it using ALIGNED PER:
>>> from hexdump import dump
>>> import asn1tools
>>> foo = asn1tools.compile_files('foo.asn', codec='per')
>>> print(dump(foo.encode('Foo1', {'foo': 0xDEAD, 'bar': {'qux': 0xF00D}, 'msg': 'Hello world'})))
DE AD F0 0D 0B 48 65 6C 6C 6F 20 77 6F 72 6C 64
Where:
DE AD -- foo = 0xDEAD
F0 0D -- bar.qux = 0xF00D
0B -- String length
48 65 6C 6C 6F 20 77 6F 72 6C 64 -- Hello world
The structure is simple and so is its serialized representation. In fact, it would look identical in DSDL, except that the byte order would be the opposite.
Now, let’s deploy the ASN.1 standard data type extensibility feature by marking Baz extensible:
Foo DEFINITIONS ::= BEGIN
Baz ::= SEQUENCE {
qux INTEGER(0..65535),
... -- EXTENSION MARKER
}
Foo1 ::= SEQUENCE {
foo INTEGER(0..65535),
bar Baz,
msg VisibleString
}
END
Repeating the above serialization example (same values), we obtain:
DE AD
00 -- NEW: Extension flag cleared (MSb), 7 padding bits.
F0 0D -- The rest is the same
0B
48 65 6C 6C 6F 20 77 6F 72 6C 64
Once again, this time having some extension fields after the extension marker:
Foo DEFINITIONS ::= BEGIN
Baz ::= SEQUENCE {
qux INTEGER(0..65535),
..., -- EXTENSION MARKER
u32 INTEGER(0..4294967295), -- New extension fields
u16 INTEGER(0..65535)
}
Foo1 ::= SEQUENCE {
foo INTEGER(0..65535),
bar Baz,
msg VisibleString
}
END
Recompile & encode two variants, without u16 and then with it:
>>> foo = asn1tools.compile_files('foo.asn', codec='per')
>>> print(dump(foo.encode('Foo1', {'foo': 0xDEAD, 'bar': {'qux': 0xF00D, 'u32': 0xabcdef12}, 'msg': 'Hello world'})))
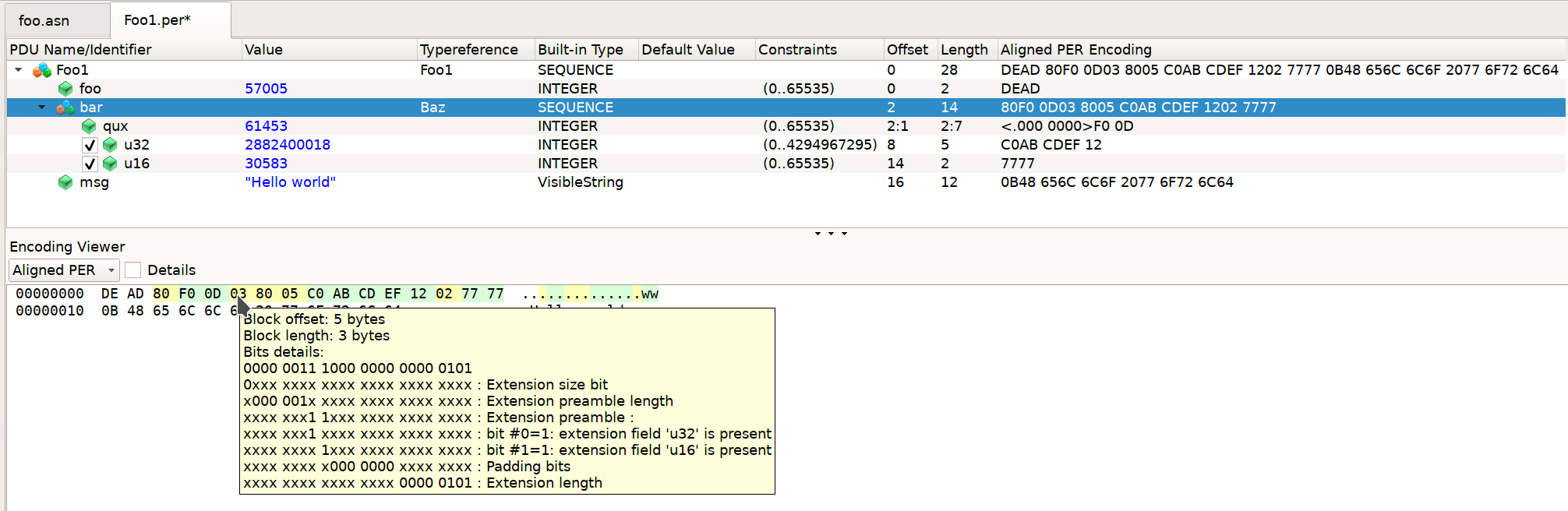
DE AD 80 F0 0D 03 00 05 C0 AB CD EF 12 0B 48 65 6C 6C 6F 20 77 6F 72 6C 64
>>> print(dump(foo.encode('Foo1', {'foo': 0xDEAD, 'bar': {'qux': 0xF00D, 'u32': 0xabcdef12, 'u16': 0x7777}, 'msg': 'Hello world'})))
DE AD 80 F0 0D 03 80 05 C0 AB CD EF 12 02 77 77 0B 48 65 6C 6C 6F 20 77 6F 72 6C 64
The resulting representation is suddenly highly complex. In order to retain compatibility with schema definitions devoid of the extension fields, the representation has been extended with detailed information about the new fields; namely, presence markers and length information. The additions shift the encoding along the self-describability spectrum. Explanation:
DE AD -- Field 'foo' = 0xDEAD
80 -- Extension flag set (MSb), 7 padding bits.
F0 0D -- Field 'bar.qux' = 0xF00D
03 -- MSb is 0 hence preamble length <= 64 octets; preamble length = 0b000001, decoded as 2; first extension field ('u32') is present
00 -- Second extension field ('u16') is missing, then 7-bit padding
05 -- Next extension length = 5 octets
C0 -- Varint length prefix = 0b11000000; 0b11 = 3, decoded as 4; 6-bit padding
AB CD EF 12 -- Field 'bar.u32' = 0xABCDEF12
0B -- String length = 11 octets
48 65 6C 6C 6F 20 77 6F 72 6C 64
DE AD -- Field 'foo' = 0xDEAD
80 -- Extension flag set (MSb), then 7 padding bits.
F0 0D -- Field 'bar.qux' = 0xF00D
03 -- MSb is 0 hence preamble length <= 64 octets; preamble length = 0b000001, decoded as 2; first extension field ('u32') is present
80 -- Second extension field ('u16') is present, then 7-bit padding
05 -- Next extension length = 5 octets
C0 -- Varint length prefix = 0b11000000; 0b11 = 3, decoded as 4; 6-bit padding
AB CD EF 12 -- Field 'bar.u32' = 0xABCDEF12
02 -- Next extension length = 2 octets
77 77 -- Field 'bar.u16' = 0x7777
0B -- String length = 11 octets
48 65 6C 6C 6F 20 77 6F 72 6C 64
While preparing the annotations, I consulted with ASN.1 Studio (this is not meant to be an advertisement, I am just unaware of any adequate open-source solutions):
Google Protobuf
Being a modern standard widely used in general ICT, this one requires no introduction.
Protobuf is a self-describing schema-based TLV-encoded little-endian byte-aligned binary format. Its expressivity is much limited compared to ASN.1 (somewhere on par with UAVCAN DSDL, perhaps), which allows it to be simple.
In the schema language, each field definition is equipped with an explicit tag. The tag is encoded together with the type information in the TLV stream. The developer may assign tags arbitrarily as long as they are unique. In a TLV format, data type extensibility is trivial to implement – new fields can be just inserted into the stream at arbitrary locations; by virtue of having unique tags, they will be simply ignored by applications reliant on an older schema where the fields are absent.
Each type, naturally, has an independent set of tag values; therefore, some form of delimited encoding is required (otherwise, tags in nested types would conflict). This is achieved through length prefixes like in my proposal.
I chose to skip constructing an example because the format is trivial and the encoding rules are well-documented; the most relevant part in the context of the current discussion is this:
Cap’n’Proto
Since it is developed by the same author as Google Protobuf, one might expect it to be similar, but it is oddly not so – the serialization format is unorthodox and rather involved (not nearly as complex as ASN.1 BER/PER though).
Cap’n’Proto is a self-describing schema-based non-TLV little-endian 64-bit-aligned (with exceptions) binary format. The bit order is also little-endian, consistent with the byte order. Being non-TLV, the field order is deduced from the schema using sophisticated rules intended to minimize the number of padding bits. Manual serialization/deserialization, much like with ASN.1, is infeasible.
This format is unusual because even though there are field tags in the schema (denoted with @), the encoding is not TLV, and the schema specification requires the tags to form a continuous ordered sequence, thus making it possible to eliminate the tag metadata from the encoded representation by arranging the encoded items in a particular well-defined order. I am not exactly clear on what was the motivation for keeping the tags in the language in the first place – perhaps it’s just to permit the user to add new fields into arbitrary positions instead of just at the end, as any purely tagless language (such as DSDL) would require.
Let us review an example. Suppose we have a basic schema like this defined in file basic.capnp:
@0x934efea7f017fff0;
struct A {
foo @0 :UInt16;
bar @1 :Baz;
baz @2 :Baz;
}
struct Baz {
qux @0 :UInt16;
}
The type of interest here is A, which, as you can see, contains two composite-typed fields bar and baz. Let’s generate a sample message where foo=0xdead, bar=0xf00d, baz=0xbeef:
>>> import capnp, basic_capnp
>>> msg = basic_capnp.A.new_message(foo=0xdead, bar=basic_capnp.Baz.new_message(qux=0xf00d), baz=basic_capnp.Baz.new_message(qux=0xbeef))
>>> msg.to_bytes().hex()
'00000000060000000000000001000200adde000000000000040000000100000004000000010000000df0000000000000efbe000000000000'
In capnp, everything is aligned to one word, which is 8 bytes. Here’s the same byte string split into words:
00 00 00 00 06 00 00 00
00 00 00 00 01 00 02 00
ad de 00 00 00 00 00 00
04 00 00 00 01 00 00 00
04 00 00 00 01 00 00 00
0d f0 00 00 00 00 00 00
ef be 00 00 00 00 00 00
The meaning is as follows:

A “segment” is a fragment of the serialized representation of a message. It follows from the fact that in capnp the worst-case message footprint is not bounded so the serializer has to guess the amount of memory that has to be allocated beforehand (it holds for most general-purpose serialization formats). If the available memory is insufficient to contain the entire message, it is split into several segments.
The pointer format is quite convoluted but there appear to be solid reasons for that – it allows one to manipulate the data without having access to the schema (hence the format is self-describing). Each composite is serialized independently and included in the outer message such that its field offsets are decoupled from its composites.
OMG DDS CDR (XCDR)
The OMG’s Common Data Representation (CDR) standard was originally defined as a platform-agnostic serialization format for CORBA. CORBA has been shown to be ill-suited for real-time applications (The Adaptive Communication Environment Object Request Broker paper), which was a contributing factor for the development and standardization of DDS.
Despite a completely different architecture, DDS builds upon some of the core parts of CORBA, such as its IDL and the transfer syntax (i.e., serialization format). DDS extends the IDL with its own specific features and defines several alternative transfer syntaxes for CDR to support extensible data types. The following normative specifications are the most pertinent to this discussion:
- General Inter-ORB Protocol – includes the original CORBA CDR specification.
- Extensible and Dynamic Topic Types for DDS – the specialization for DDS.
Among the standards reviewed in this write-up, DDS CDR (also known as XCDR, X for extended, not to be confused with XDR) is the closest in spirit, feature set, and design objectives to UAVCAN. DDS CDR is significantly more complex and more feature-rich than UAVCAN DSDL due to its wider scope and the fact that hard real-time safety-critical applications are not within the scope.
CDR provides the most comprehensive support for data type extensibility along with a set of formalized compatibility criteria and a well-developed theoretical background. The type system defines three type extensibility categories: FINAL (the type is not extensible, like DSDL v0 or @final), APPENDABLE (like DSDL v1 – fields can be added at the end), and MUTABLE (pure self-describing TLV encoding, like Google Protobuf or ASN.1 BER, allows arbitrary modification of the type).
Further, in order to enlarge the set of usage scenarios where different types can form interoperable interfaces, explicit type coercion rules are defined as the so-called Try Construct behavior, which defines one of the three possible deserialization failure handling policies: DISCARD (the representation that cannot be deserialized using the available schema invalidates the entity that contains it, namely the higher-level composite or the container if any, this is the default behavior); USE_DEFAULT (fallback to the default value); TRIM (applies only to variable-length containers instructing the decoder to discard the excess elements).
A dedicated QoS policy TypeConsistencyEnforcementQosPolicy allows the participants to choose whether to allow automatic coercion of different yet compatible (assignable) types.
The type truncation, subtyping, and extension features are nearly equivalent to those of UAVCAN DSDL. One unbeatable advantage of the XCDR specification though is that it is an endless source of useful information about the world at large, pondering such existential matters like the number of legs a snake has or whether giraffes have scales.

All binary formats defined by XCDR are byte-oriented with liberal use of padding to ensure natural alignment for most members (e.g., a 32-bit integer is guaranteed to be 4-byte aligned, unless it is packed into an opaque container; larger items may have smaller alignment depending on the flavor). Enumeration members are 32-bit unsigned integers by default; variable-size items (like sequences) are prefixed with a fixed-size 16/32-bit unsigned integer length. Padding is well-specified to ensure unequivocal canonical representations. The byte order is either little- or big-endian, selected by the serializer; the bit order is always little-endian.
Fixed-size 32-bit length prefixes can also be found in Cap’n’Proto and XDR (not to be confused with XCDR), unlike Protobuf, ASN.1, or some binary JSON formats that tend to leverage variable-length length (sic!) fields.
Nested objects can be serialized in three formats: non-delimited, where the nested object is simply inserted in-pace as if it was replaced by its fields (which I call “non-orthogonal” or “flat”); delimited, where the nested object is prefixed by a length field (like Protobuf); or as a TLV parameter list (which is then terminated by a delimiting symbol, like some JSON-based binary formats).
UAVCAN is comparable in its commitment to support the evolution of data types to DDS, but its type system is far less rigorously modeled and the specification pays absolutely no regard to snakes or giraffes. UAVCAN delegates all compatibility-related concerns to the integrator by saying merely (5.1.2 Port compatibility):
The system integrator shall ensure that nodes participating in data exchange via a given port use data type definitions that are sufficiently congruent so that the resulting behavior of the involved nodes is predictable and the possibility of unintended behaviors caused by misinterpretation of exchanged serialized objects is eliminated.
…whereas the DDS specification does a great job of formally exploring the data type relations. If the UAVCAN type system model is developed further, it is still unlikely to reach the same level of complexity because UAVCAN intentionally omits the support for entities with a high degree of runtime variability (such as by-default-optional data members, arbitrary ordering of fields, runtime-defined types, etc).
The plain-CDR (CORBA) encoding is very much like DSDL v0; here is a basic example:
struct Baz
{
uint16 qux;
// uint16 waz; // Commented out
};
struct Foo
{
Baz bar;
uint16 foo;
string msg;
};
Suppose we compile the IDL and publish a message initialized like:
Foo st;
st.foo(0xDEADU);
Baz bz;
bz.qux(0xF00DU);
st.bar(bz);
st.msg("Hello world");
We capture the message using Wireshark and it helpfully dissects the data packet for us:
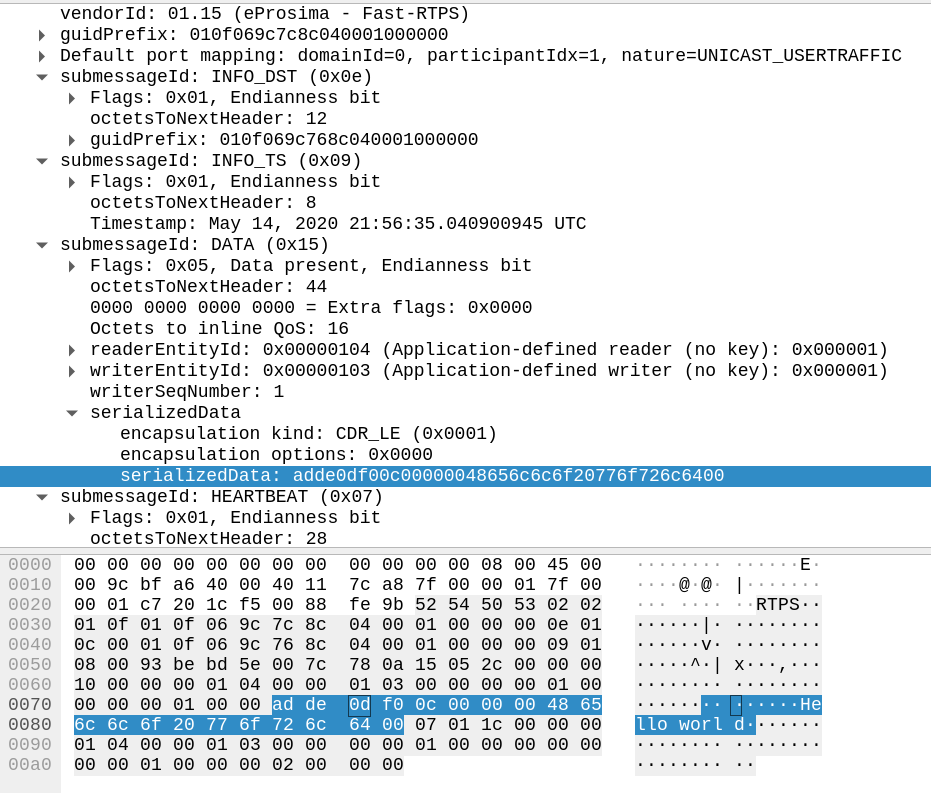
I am running this on my little-endian PC hence ad de 0d f0 stands for 0xdead, 0xf00d, followed by the four-byte string length prefix 0xC = 12, followed by the null-terminated greeting. That’s it.
If you uncomment the commented-out field in the example, things will break because the default non-delimited encoding does not support mutable/appendable types. Unfortunately, most open-source DDS implementations as of 2020 do not support extensible data types so it would be hard to provide a practical demo, but then again, it is hardly necessary because the specification seems clear enough (as far as complex specifications go).
First, recall that XCDR defines multiple encodings. This sounds bad enough but the specification ships a clarification:
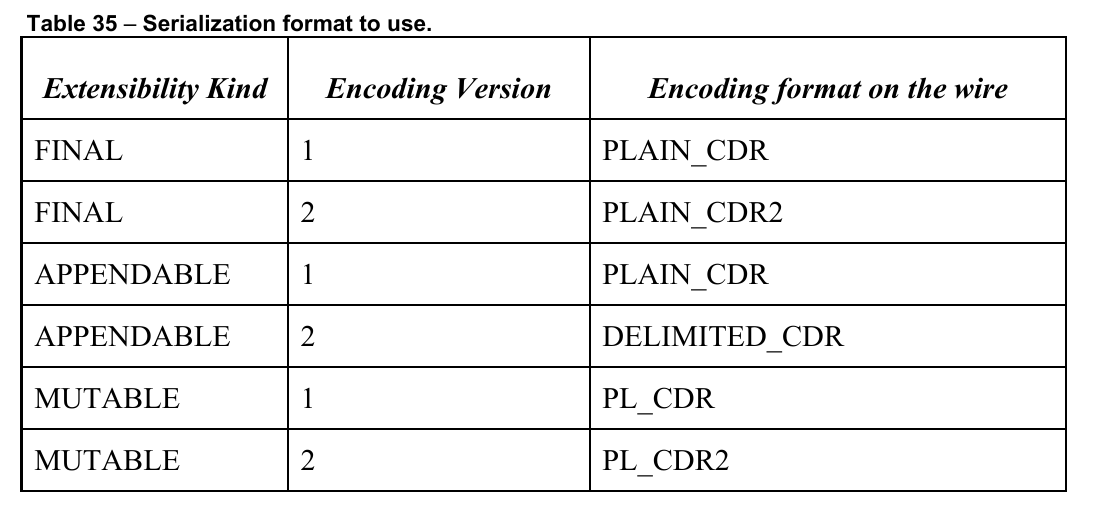
PLAIN_CDR and its second version use the most naive direct flat encoding. The second version merely adjusts some unimportant details like padding that do not warrant attention right now.
DELIMITED_CDR is like PLAIN_CDR2 but it injects a length prefix before APPENDABLE objects, thus facilitating orthogonal serialization.
PL_CDR and its second version are pure TLV like Protobuf or ASN.1 BER.
We could go into details here but I perceive that might distract the discussion a bit too much. The DDS spec is complex but far more manageable than ASN.1.
XDR
Although not widely used in new designs, the External Data Representation (XDR) format deserves an honorable mention. It is defined in IETF RFC 4506. Being an old technology, it is big-endian and lacks any extensibility/versioning features. The specification defines a very simple dedicated schema language.
This is a non-self-describing schema-based non-TLV-encoded big-endian 32-bit-aligned binary format. The field encoding is fully static and flat; nested objects are serialized in-place as if the fields of the nested object were just to drop-in replace the nested reference.
A basic serialization example can be found in the RFC.
This is probably the simplest format for which there is a formal specification. Overall this would be a solid piece of technology for simple applications if not for the lack of extensibility and the big-endian byte order.
Summary
I should emphasize once again that practical implementations have ambiguous features so the classification is intended to apply only to the most common use cases.
| Format | TLV | Self-desc. | Extensible | Byte order | Composite nesting |
|---|---|---|---|---|---|
| ASN.1 BER | yes | yes | yes | big | length prefix, extension flags, delimiting symbols |
| ASN.1 PER | no | no | yes | big | length prefix, extension flags, delimiting symbols |
| Google Protobuf | yes | yes | yes | little | length prefix |
| Cap’n’Proto | no | yes | yes | little | pointer-based |
| XCDR v1 PLAIN_CDR FINAL | no | no | no | any | flat (direct in-place) |
| XCDR v1 PL_CDR APPENDABLE | yes | yes | yes | any | delimiting symbols |
| XCDR v1 PL_CDR MUTABLE | yes | yes | yes | any | delimiting symbols |
| XCDR v2 PLAIN_CDR2 FINAL | no | no | no | any | flat (direct in-place) |
| XCDR v2 DELIMITED_CDR APPENDABLE | no | no | yes | any | length prefix and delimiting symbols |
| XCDR v2 PL_CDR2 MUTABLE | yes | yes | yes | any | length prefix and delimiting symbols |
| XDR | no | no | no | big | flat (direct in-place) |
| BSON | yes | yes | yes | little | length prefix |
| UBJSON | yes | yes | yes | little | length prefix or delimiting symbols |
| CBOR | yes | yes | yes | big | length prefix or delimiting symbols |
| UAVCAN DSDL | no | no | little |