We have a new record – approx. 2h on the call. There should be an emoji of a unicorn puking rainbow.
Tomorrow morning @tsc21 will be working hard on defining the low-level requirements for the current sprint. We may or may not have another call to discuss that afterward.
Here is the image of the drawing I made on the (not so) white board:
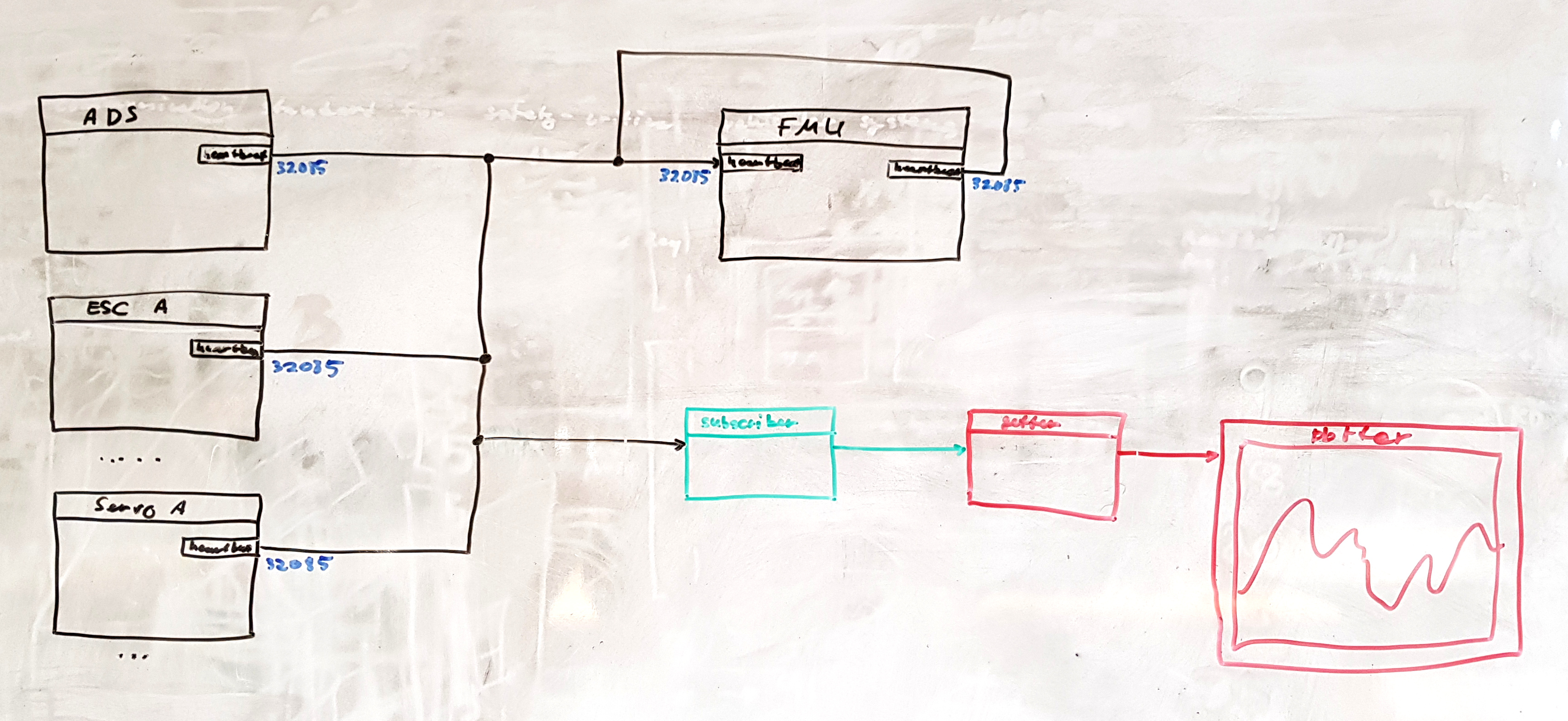
Important things on the image:
- Inputs are on the left, outputs are on the right (GUI Tool – Next Generation - #53 by pavel.kirienko)
- The local data manipulation entities – namely, the subscriber, the getter, and the plotter – are outside of the scope of the current sprint but the design shall allow their introduction later.